## Importing data from a CSV file
data <- read_csv("path/to/your/file.csv")12 Importing CSV Files
CSV (Comma-Separated Values) files are one of the most common formats for storing and sharing data. They are simple text files where each line corresponds to a row of data, and columns are separated by commas.
12.1 Importing through RStudio IDE-Generated Code
RStudio provides a user-friendly, graphical interface to import data files. This is especially helpful for beginners because it eliminates the need to write code manually and helps you understand the process as the IDE generates the import code for you.
Steps to Using the RStudio IDE:
Open the Files Pane: In the bottom-right of the RStudio interface, find the Files Pane, where you can browse the files on your computer.
Select the CSV File: Click on the
.csvfile that you want to import.Open the Import Wizard: When you select the file, RStudio automatically opens an import wizard to guide you through the process.
Configure Import Settings: In the import wizard, you can adjust settings based on your dataset. Here are the key options:
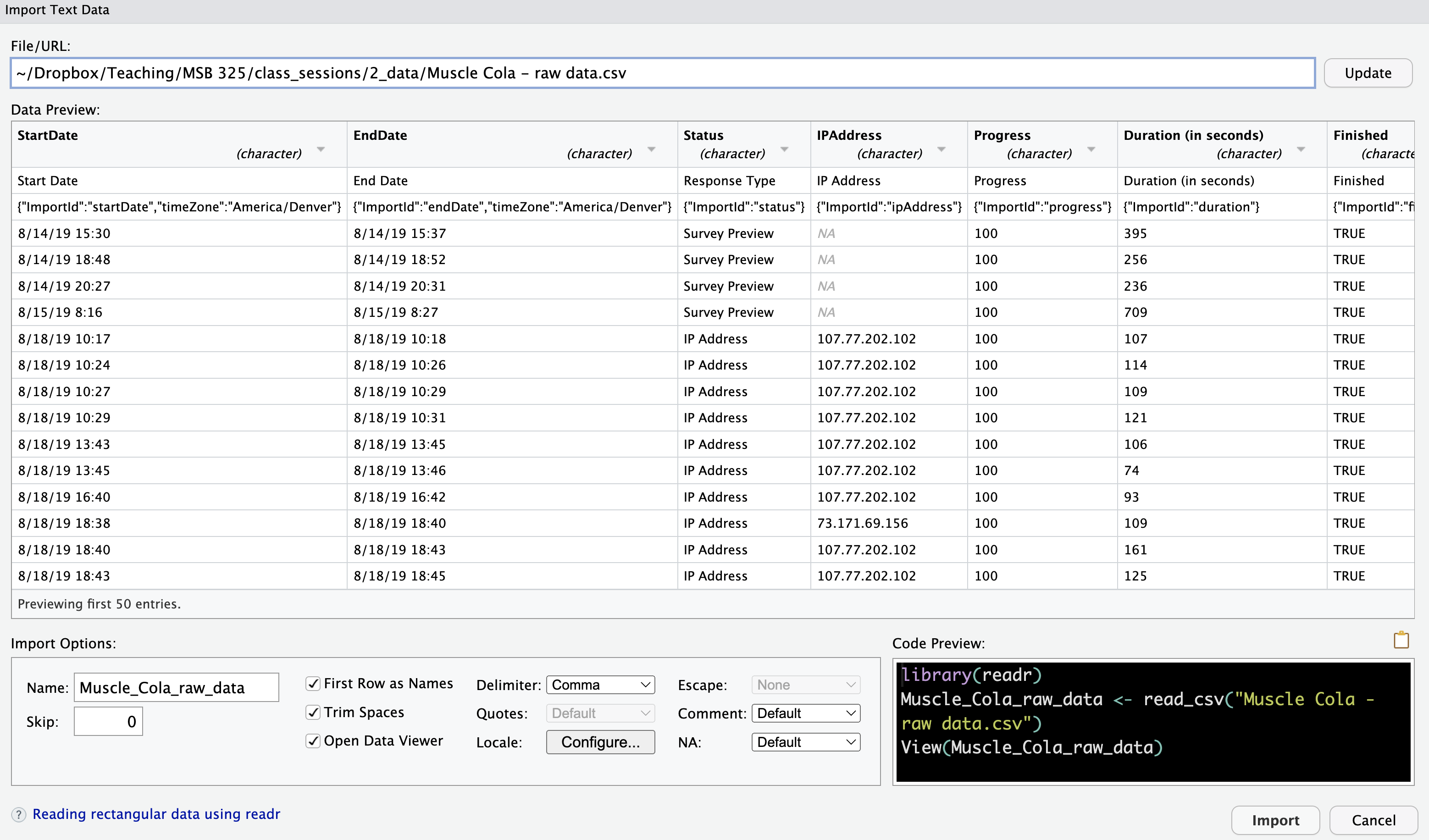
RStudio IDE Settings for CSV Files - Name: Choose a name for your dataset. R will offer a default, but you can customize it.
- Skip Rows: Indicate how many rows to skip from the top of the file (e.g., for metadata rows).
- First Row as Names: If your file has column names in the first row, check this option.
- Trim Spaces: Remove any extra spaces at the beginning or end of values.
- Open Data Viewer: Check this box to preview the imported data in a table-like view.
- Delimiter: By default, the delimiter is a comma (
,), but if your file uses something else (e.g., a semicolon), you can change it here. - Quote: For handling text fields in your CSV that use quotes (e.g.,
"New York, NY"). - Locale: Set regional settings for dates or number formats (e.g., European date formats).1
- Escape Characters: Handle special characters that need to be “escaped,” like quotes or commas.2
- Comment Lines: Ignore lines marked with specific characters (e.g., lines that start with
#). - NA Values: Specify how missing values are represented (e.g.,
NA,NULL,?).
Adjust Data Types: At the top of each column in the data preview, you can see the data type (e.g., character, numeric). Change the type if R has incorrectly guessed the data type:
- Numeric as Character: Change text fields that should be numbers.
- Dates as Character: Convert date fields to a proper date format.
- Factors: Change character columns to factors (categories) if needed.
Click “Import”: Once you’ve adjusted the settings, click the “Import” button to bring the data into R.
View the Data: The data opens in RStudio’s Data Viewer, where you can inspect it visually.
Save the Import Code: The IDE automatically generates R code for the import and runs it in the console. Copy this code into your script to reuse it later, so you don’t have to reconfigure the settings manually each time.
Advantages of Using the IDE Method
- Easy to Use: You don’t need to memorize code or syntax—just click through the interface.
- Learn as You Go: The IDE generates code for you, which helps you learn R’s import functions over time.
- Efficient for Quick Imports: Great when you need to quickly import and inspect new files.
12.2 Importing through AI-Generated Code
While importing .csv data through the RStudio IDE is intuitive and visual, it has its limitations. The process can be manual, and any changes you make must be repeated each time you want to import the data. This is because the IDE doesn’t automatically store the import code in your R script, making the process not automatically reproducible. This is where AI-generated code can be a powerful solution.
Why Use AI-Generated Code?
Using AI to generate code opens up new possibilities for data analysis. Here are some of the benefits:
- Efficiency: AI can write code quickly, reducing the time you spend manually configuring options in the IDE. This means you can focus more on analyzing the data rather than the import process.
- Reproducibility: When AI generates code, it can be directly included in your R script, ensuring that your data imports are consistent each time you run the script. This reproducibility is crucial for accurate and reliable data analysis.
- Flexibility: AI can handle more complex scenarios by understanding your specific requirements. You can use prompts to specify exactly how your data should be imported, including custom configurations that might be harder to set up manually.
- Learning Opportunity: Seeing the code generated by AI can help you understand R more deeply. By examining and tweaking the code, you learn how to accomplish specific tasks, making you more comfortable with coding in general.
Solutions for Reproducibility
To make your workflow more efficient and reliable, consider the following approaches:
- Copy the Code from the Console: After using the RStudio IDE to import data, copy the generated code from the console into your script. This allows you to reproduce the import process every time you run your script, preserving the settings you configured in the IDE.
- Generate Code Using AI: An even more efficient solution is to use AI to generate the import code for you. By providing a well-crafted prompt, you can ensure reproducibility from the start without relying on manual steps. This method can save time and reduce the risk of errors.
Importing Simple .csv Data with AI-Generated Code
To import a simple .csv file using AI, provide the name of your .csv file and the desired name for the dataset in R.
AI Prompt:
Importing .csv Data:
“Please provide the tidyverse code to import a .csv file named tb.csv and name the resulting tibble tb_data.”
Importing Qualtrics .csv Data with AI-Generated Code
Qualtrics exports often contain metadata in both rows and columns. For example, the first and third rows, as well as certain columns, might include metadata you need to exclude. To handle this, you can use a more complex AI prompt like the one below.
AI Prompt:
Importing .csv Data with Metadata:
Please provide the tidyverse code to import a CSV file named ‘“long Qualtrics file name.csv”’ with the following requirements:
- The first row contains metadata and should be skipped.
- The second row contains column names and should be used as headers.
- The third row contains metadata and should be excluded.
- The columns from ‘Start Date’ through ‘User Language’ also contain metadata and should be excluded from the dataset.
- Ensure that the data types are converted appropriately after import.
- Name the resulting tibble
descriptive_name_data.
By incorporating AI into your workflow, you can streamline the data import process, making it faster, more reliable, and easier to maintain. You maintain reproducibility and can easily handle more complex import tasks, such as skipping metadata rows and columns. This approach is especially useful when working with complex datasets or repetitive tasks where consistency is key.
12.3 Importing Data with Reference Code
Copying and adapting reference code is a time-tested approach to coding. Before the advent of AI tools, this was the standard way most developers and analysts wrote code. Reference code allows you to take existing examples—whether from this book, R for Data Science, or community sites like Stack Overflow—and customize them to fit your specific needs.
You might worry that copying and modifying code feels like cheating, but it’s not. In fact, it’s how coding is done—and how coding is learned. Using and adapting reference code is a skill that builds understanding and confidence. This chapter provides demonstration tidyverse code to import CSV files into R. You’re encouraged to copy it into your own scripts and edit it to suit your circumstances.
Owning Your Code
Whether you use the RStudio IDE, AI tools, or reference code to generate your import scripts, the responsibility for the resulting code lies with you. The accuracy and quality of generated code depend entirely on the quality of the prompts or edits you provide. Simply put: you own the code you use.
Owning your code means:
- Understanding the Code: Knowing what each part of the code does and ensuring it performs the task you intended.
- Verifying the Output: Checking that the code behaves as expected and produces the desired results.
- Debugging Errors: Identifying and fixing issues when something goes wrong.
- Adapting the Code: Making adjustments for different datasets or contexts.
Even if you rely on tools to generate code, understanding what the code does and how to modify it ensures that you stay in control. Blindly trusting generated scripts without understanding their purpose can lead to errors or unintended outcomes.
The Value of Reference Code
Reference code provides a clear starting point. By studying and adapting examples, you can:
- Learn how common functions like
read_csv()work in practice. - Use templates for specific challenges, such as skipping metadata rows or selecting specific columns.
- Recognize and validate the structure of IDE- or AI-generated code by comparing it against trusted examples.
- Develop troubleshooting skills by understanding how to fix or refine reference code for different situations.
This section guides you through typical scenarios for importing .csv files, including handling special cases like Qualtrics survey data. Use these templates to deepen your understanding, verify generated code, and build a personal library of solutions that you can reuse and adapt.
Importing a Simple CSV File
To import a CSV file into R, we use the read_csv() function from the readr package, part of the tidyverse:
Replace "path/to/your/file.csv" with the actual file path of your CSV file. This method is ideal for structured data that’s exported from spreadsheets, databases, or other software.
Importing Qualtrics .csv Data
Let’s go through a more complex example of importing Qualtrics data that includes metadata. We will build a single integrated code block, along with explanations for each step.
Handling Qualtrics Metadata
Metadata is “data about data.” In the context of a Qualtrics survey, it refers to the additional information generated by the survey platform about the performance of your survey. This can include details about when the survey was completed, how long it took, the version of the survey, and more. While metadata is important to evaluating the quality of the survey, it can interfere with your analysis of the survey data.
This metadata can be in the form of extra rows or columns that should be excluded. Below, we’ll demonstrate how to:
- Skip Rows: To ignore metadata rows during import.
- Remove Unwanted Columns: To exclude metadata columns.
- Convert Data Types: To correct column types after import.
Here’s a consolidated example for handling Qualtrics metadata during and after import:
## Import the CSV data and skip the first (metadata) row
descriptive_name_data <- read_csv("long Qualtrics CSV file name.csv",
skip = 1) |>
## Remove unwanted columns
select(!(column1:columnN)) |> ## where column1 is the first column of metadata and columnN is the last column of metadata.
slice(-1) |> ## Remove the remaining row of metadata
type_convert() ## Reevaluate the data typesExplanation:
skip = 1: Skips the first row (metadata).select(!(column1:columnN)): Removes metadata columns 1 through N.slice(-1): Deletes the (new) first row (old third row) that still contains metadata.type_convert(): Automatically converts the data to appropriate types after cleaning.
Understanding and Verifying Generated Code
While the RStudio IDE and AI can generate similar code, slight differences can significantly impact functionality. Let’s look at how to spot these:
- Check for Correct Syntax: Make sure the function names, parameters, and file paths match your dataset.
- Verify Skipped Rows and Selected Columns: Confirm that the metadata has been correctly removed. Compare your results with the raw file to ensure accuracy.
- Watch for Correct Data Types: After running
type_convert(), useglimpse()to verify that columns have been correctly identified as numeric, character, or date.
If you see problems in your imported data, consider the following debugging tips to clean your import code:
- Mismatched Column Types: If you still see unexpected column types, re-examine your data after removing metadata. Sometimes extra characters or spaces can cause misclassification.
- Incorrect Rows or Columns: Use
head()andsummary()to verify that your data was imported correctly. - Unexpected Errors: Make sure all necessary libraries are loaded. Check for typos in your column or file names.
12.4 Exercise: Import CSV Data
Try it yourself:
Let’s apply these steps to a real example. An entrepreneur had the idea to start a popup cupcake stand that would show up outside of university classrooms between classes. Students would be able to get a snack without leaving the classroom area or carrying it from home. The dataset is in a file named cupcakes.csv and the file is located in the data subdirectory of this document. Let’s import this CSV data file and deal with the metadata inserted by the Qualtrics survey:
- Name the imported data object
cupcakes_data. - Skip the first (metadata) row.
- Delete the columns of metatdata (columns 1 through 17 are metadata; columns 18 through 26 are survey data)
- Delete the new first row (original third row) of metatdata.
- Re-evalutate the data types
Hint 1
Change the name of the data object as well as the argument to the read_csv() function to import the cupcakes data. Skip the first and third rows (metadata) and delete columns 1 through 17. Re-evaluate the data types.
Hint 2
- Change the name
datatocupcakes_data - Change the path to the file to
data - Change the name of the file to be imported to
cupcakes.csv - Add the skip argument to the
read_csvfunction - Delete the columns of metadata
- Delete the (new) first row
- Convert the data types of the remaining variables.
Change the code to match the specifics of importing the csv file cupcakes.csv.
cupcakes_data <- read_csv("data/cupcakes.csv",
skip = 1) |>
select(!(1:17)) |>
slice(-1) |>
type.convert()- Specify the data object to be
cupcakes_data - Specify the path to the data to be
"data" - Change the name of the file to be imported to
cupcakes.csv - Add the skip argument to the
read_csvfunction - Delete the columns of metadata
- Delete the (new) first row
- Convert the data types of the remaining variables.
Mastering how to write, understand, and verify code will make you more confident in using R for data analysis, even when relying on tools like the IDE or AI to generate code for you. Always make sure you know what your code is doing and be prepared to adjust and debug as needed.
12.5 Advantages of Using CSV Files with R
Universal Format: CSV (Comma Separated Values) is a widely supported format across different platforms and tools, making it easy to share and transfer data.
Lightweight and Efficient: CSV files are simple text files, so they are lightweight and can be processed quickly by R without needing extra software or dependencies.
Standard Structure: CSV files have a straightforward row-and-column structure, making them easy to work with in R using functions like
read.csv()orreadr::read_csv().Human-Readable: Since CSV files are plain text, you can easily open them in any text editor or spreadsheet software to view the raw data.
Minimal Formatting: CSV files don’t include complex formatting like fonts, formulas, or colors. This reduces the risk of issues during import, making it easier to focus on the actual data.
Preferred Format in Data Science: CSV is widely used by data science professionals due to its simplicity and compatibility. It avoids the problems associated with proprietary formats and is ideal for storing raw data.
Mastering CSV imports allows you to work efficiently with data in its simplest form, integrating seamlessly into your R workflow for analysis and visualization.
Leave the Locale at its default setting unless you are working with European CSVs where the file uses commas for decimals and periods for thousands separators.; dealing with data from multiple countries with different encoding, date formats, or language-based special characters; or when text includes special non-ASCII characters (e.g., accented letters).↩︎
In CSV files, escaping is necessary when you want to include characters that otherwise have a special meaning in the file, such as the delimiter (comma) or quotation marks within a field, without breaking the file’s structure.↩︎