install.packages("readxl") ## Install the package (run once)
library(readxl) ## Load the package13 Importing XLSX Files
Excel is a widely used tool in business for data collection and analysis. R makes it easy to import Excel data, thanks to the readxl package. Whether you’re working with .xls or .xlsx formats, readxl provides a straightforward way to read Excel files into R.
13.1 Installing and Loading the readxl Package
To work with Excel files in R, you need the readxl package. If it’s not already installed, you can install and load it with the following commands:
Once the readxl package is installed, you don’t need to install it again unless you are updating to a new version. However, you do need to load the package with library(readxl) every time you run your R script.
To avoid unnecessary installs, comment out the install.packages() line after the first installation. You should only keep the library(readxl) line active when running your code.
#install.packages("readxl") ## Install the package (run once)
library(readxl) ## Load the package13.2 Importing Excel Data through RStudio IDE-Generated Code
RStudio provides a graphical interface for importing Excel files, which can be easier than writing code manually. This approach allows you to visually select your settings and have RStudio generate the corresponding R code for you.
Steps to Import Excel Files Using RStudio IDE:
Navigate to the Files Pane: In the bottom-right corner of the RStudio interface, find the Files Pane where you can browse your local files.
Select the Excel File: Click on the
.xlsxfile you want to import.Open the Import Wizard: RStudio will automatically launch the import wizard for Excel files.
Configure the Import Settings:
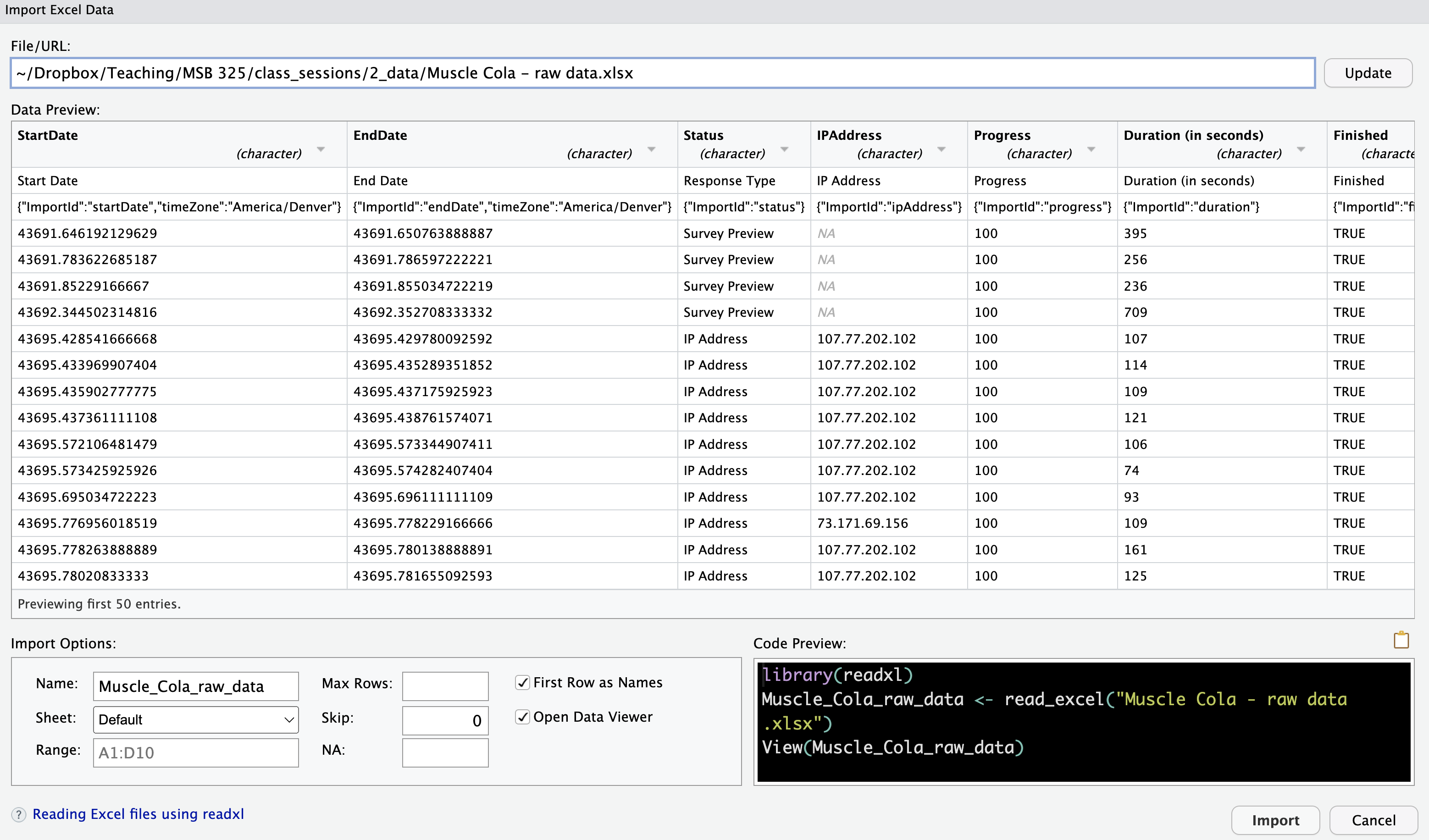
RStudio IDE Settings for Excel Files - Name: Specify the name of the imported tibble (data frame). R will suggest a default name, but you can change it.
- Sheet: Choose the worksheet you want to import (default is the first sheet).
- Range: Optionally, specify the range of cells to import if you only need part of the data.
- Max Rows: Limit the number of rows if needed.
- Skip: Skip a specific number of rows (useful for ignoring headers or metadata).
- NA Strings: Define any values that should be treated as missing (NA).
- First Row as Names: Check this box if the first row contains column names.
- Open Data Viewer: Optionally, check this box to view the data after import in RStudio’s spreadsheet-like viewer.
Save the Import Code: After completing the import, copy the generated R code from the console and paste it into your R script. This way, you can reuse the code for future imports without needing to reconfigure the settings.
13.3 Importing Excel Data through AI-Generated Code
Importing Simple .csv Data with AI-Generated Code
Importing Excel spreadsheets (.xlsx) through the RStudio IDE is intuitive and visual but it is also manual and not automatically reproducible. An AI can provide code for you R script that will work every time you need to import the data.
AI Prompt:
Importing .xlsx Data:
“Please provide the tidyverse code to import a .xlsx file named data_file.xlsx and name the resulting tibble descriptive_name_data.”
Importing Qualtrics .xlsx Data with AI-Generated Code
Qualtrics exports often contain metadata in both rows and columns. For example, the first and third rows, as well as certain columns, might include metadata you need to exclude. To handle this, you can use a more complex AI prompt like the one below.
AI Prompt:
Importing .xlsx Data with Metadata:
Please provide the tidyverse code to import an Excel file named "long Qualtrics file name.xlsx" with the following requirements:
- The first row contains metadata and should be skipped.
- The second row contains column names and should be used as headers.
- The third row contains metadata and should be excluded.
- Columns A through R (i.e.,
Start DatethroughUser Language) contain metadata and should be excluded from the dataset. - Ensure that the data types are converted appropriately after import.
- Name the resulting tibble
descriptive_name_data.
By using AI to generate the import code, you maintain reproducibility and can easily handle more complex import tasks, such as skipping metadata rows and columns.
Owning Your Code
When using RStudio’s IDE or AI-generated tools, the quality and reliability of the code depend on the clarity of your prompts or configuration choices. Owning the code means taking responsibility for what the code does, verifying its output, and being able to debug or modify it if needed. This becomes especially important when working with more complex data formats like Excel files.
Understanding and being able to read the code allows you to:
- Verify the functionality: Make sure the data imports correctly and any specified settings work as expected.
- Troubleshoot errors: Recognize and resolve common issues, such as misinterpreted data types or skipped rows.
- Adapt to new requirements: Modify code for different Excel files, sheets, or specific data ranges.
13.4 Importing Qualtrics .xlsx Data
The read_excel() function from the readxl package is typically used to import Excel files into R. Below is a reference template that you can compare with your generated code:
## Template for importing Excel data
data <- read_excel("path/to/your/file.xlsx",
skip = 1) |> ## Skip the first row of metadata
slice(-1) |> ## Remove the new first row (originally the third row) of metadata
select(-(1:N)) |> ## Exclude columns from column 1 through column N - can also use column headers
type.convert(). ## Re-evaluate the data types for all columnsExplanation:
skip = 1: Skips the first row of metadata, making the second row the column headersslice(-1): Remove the new first row (originally the third row) of metadataselect(-(1:N)): Exclude columns of metadata (1 through N) by their column numbers - can also exclude by their column namestype_convert(): Automatically converts the data to appropriate types after cleaning.
Replace “path/to/your/file.xlsx” with the actual file path, and modify the arguments based on your specific data needs. This code provides more control over the import process, allowing you to skip metadata rows, select a specific sheet, or limit the import to a defined range of cells.
13.5 Exercise: Importing Excel Data
Try it yourself:
The cupcake entrepreneur is also considering a popup cinnamon roll stand. The Qualtrics dataset is an Excel file named cinnamon_rolls.xlsx and the file is located in the data subdirectory of this document. It has two sheets. The first sheet contains all of the original data where the first and third rows are meta data and columns A through N are also meta data. The second sheet has been edited in Excel to remove all meta data to include only customer data.
It is more reproducible to use code during data import than to manually edit the spreadsheet. Change the code to successfully import only the customer data (excluding the meta data) from the first sheet of the cinnamon rolls Excel file. Note that the customer data is found in columns O through X and there were 23 respondents.
Let’s import this Excel data file:
- Name the data object
cinnamon_rolls_data - Skip the first row of metadata
- Remove the remaining row of metadata if there is one
- Exclude columns of metatdata
- Re-evaluate the data types
Hint 1
Change the arguments of the read_excel() function to specify the name of the data, and the skip argument to skip the first row of metadata. Then delete the remaining row of metadata (if there is one), exclude the columns of metadata, and re-evaluate the data types.
Hint 2
- Change the data object name to
cinnamon_rolls_data - Set the
skipargument to exclude the first row of metadata - Delete the remaining row of metadata (if there is one) with
slice() - Remove the columns of metadata with
select() - Re-evaluate the data types with
type.convert()
Change the code to skip the first row of metadata making the second row column headers. Then remove the new first row of metadata because there is one, then exclude columns 1 through 14 containing metadata, and re-evaluate the data types.
cinnamon_rolls_data <- read_excel("data/cinnamon_rolls.xlsx",
skip = 1) |>
slice(-1) |>
select(-(1:14)) |>
type.convert()
cinnamon_rolls_data- Specify the data object to be
cinnamon_rolls_data - Specify the path to the data to be
"data" - Change the name of the file to be imported to
cinnamon_rolls.xlsx - Skip the first row of metadata with
skip = 1 - Remove the new first row of metadata with
slice(-1) - Exclude columns 1 through 14 that contain metadata with
select(-(1:14)) - Convert the data types of the remaining variables with
type.convert()
13.6 Advantages of Using Excel with R
- Widely Used: Excel is one of the most popular spreadsheet tools, and many organizations use it to store data. Learning how to import Excel files into R allows you to leverage existing data sources efficiently.
- Multi-Sheet Support: Excel often contains multiple sheets of data, and
readxlmakes it easy to access specific sheets. - No Need for External Dependencies: Unlike some other methods,
readxldoes not require external Java or Perl dependencies, making it lightweight and straightforward to use.
By mastering Excel imports, you’ll be able to integrate datasets stored in spreadsheets into your R workflow seamlessly, allowing for further manipulation, analysis, and visualization.